

サイバーエージェントが2025年1月27日に発表した新しい大規模言語モデル(LLM)「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」が、AI開発者の間で大きな注目を集めています。この記事では、このモデルの特徴、使用方法、そして他のモデルとの比較について詳しく解説します。
DeepSeek R1の大元のモデルの使い方は以下よりご覧ください。
DeepSeek R1とは?使い方、料金、ChatGPT o1と比較まで徹底解説

 所有資格:Google AI Essentials
所有資格:Google AI Essentials
この記事はこんな人におすすめ
・サイバーエージェントの日本語対応させた「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」が気になる
・「DeepSeek」はo1より頭いいって本当?
サイバーエージェントの開発した「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」とは?
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は、中国のスタートアップDeepSeekが開発したLLM「DeepSeek-R1」をベースに、サイバーエージェントが日本語能力を強化したモデルです。このモデルは、「DeepSeek-R1-Distill-Qwen-14B/32B」に日本語を追加学習させることで、日本語での高度な自然言語処理を可能にしました。
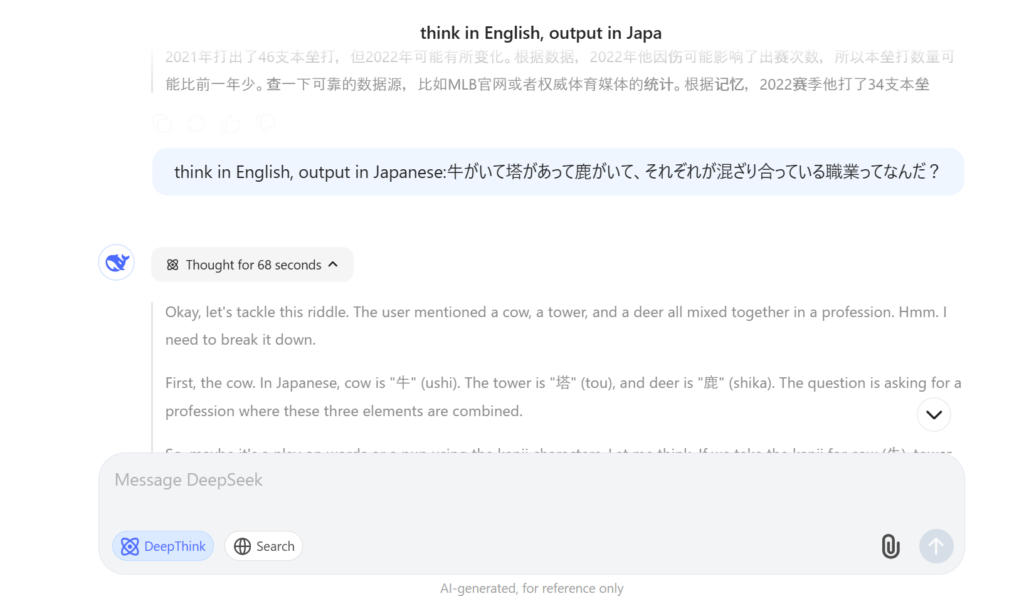
「DeepSeek-R1」でも日本語で回答してくれるのですが、基本的に中国語か英語が主になり、プロンプトを「think in English, output in Japanese:」とつけないと日本語で最後回答を返してくれませんでした。詳細は以下で確認できます。

モデルの特徴
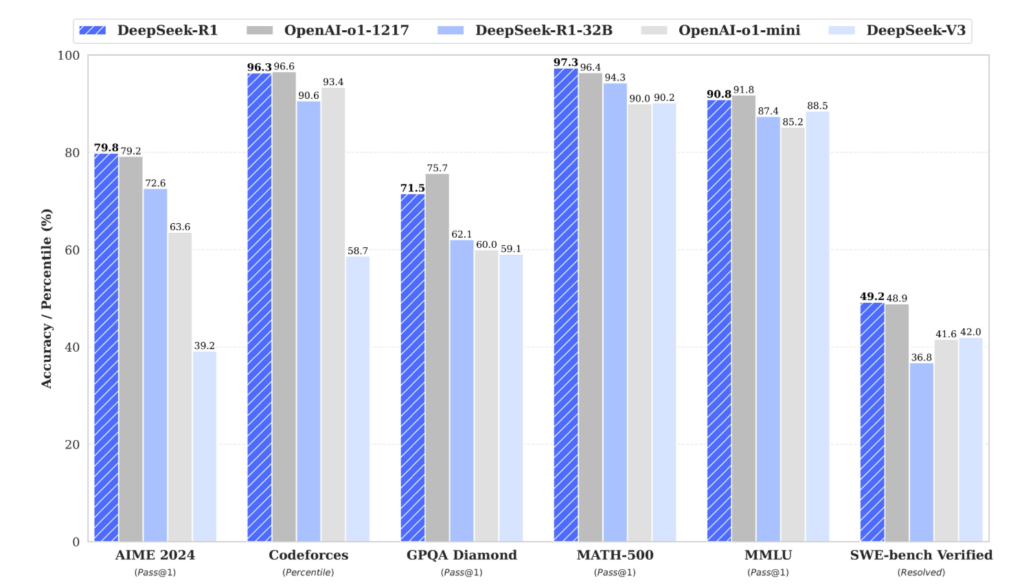
- 高性能: DeepSeek-R1は一部の分野で米OpenAIのLLM「o1」に匹敵する性能を持つとされています。
- 日本語対応: 日本語の追加学習により、日本語での高度なタスク処理が可能です。
- オープンソース: Hugging Face上で公開されており、誰でも利用可能です。
- 複数のバージョン: 14Bと32Bの2つのバージョンが用意されています。
このモデルの登場により、日本語でのAI開発がより身近になり、多くの開発者や企業が高度な自然言語処理を活用できるようになることが期待されています。
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は無料?
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は、完全に無料で利用することができます。サイバーエージェントは、このモデルをHugging Face上で公開しており、誰でも自由にダウンロードして使用することが可能です。
無料でできるものの、環境構築は無料では難しいです。
無料提供の意義
- AI技術の民主化: 高性能なLLMを無料で提供することで、AI技術へのアクセスを広げています。
- 日本語AI開発の促進: 日本語に特化したモデルを無料で提供することで、日本国内でのAI開発を加速させる可能性があります。
- 研究と開発の促進: 無料で利用できることで、学術研究や新しいアプリケーションの開発が促進されます。
無料で提供されることで、個人開発者から大企業まで、幅広いユーザーがこのモデルを活用できるようになります。これにより、日本のAI技術の発展に大きく貢献することが期待されています。
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は商用利用可能?
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は、MITライセンスの下で公開されており、商用利用も可能です。これは、開発者や企業にとって非常に重要な特徴です。
MITライセンスの特徴
- 自由な使用: ソフトウェアを自由に使用、複製、変更、配布することができます。
- 商用利用の許可: 営利目的での使用が明示的に許可されています。
- 最小限の制限: 著作権表示とライセンス条項の保持以外に大きな制限がありません。
商用利用の可能性
- 製品開発: 企業は「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」を自社製品に組み込むことができます。
- サービス提供: このモデルを使用したAIサービスを開発し、提供することが可能です。
- カスタマイズ: 企業のニーズに合わせてモデルをさらに調整し、独自のソリューションを作成できます。
商用利用が可能であることは、このモデルの価値を大きく高めています。企業は、高性能な日本語LLMを無料で利用し、自社のビジネスに活用することができます。これにより、日本のAI産業全体の成長が促進されることが期待されます。
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」の使い方
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」の使用方法は比較的シンプルですが、いくつかの手順を踏む必要があります。以下に、基本的な使用方法を説明します。
1. 環境準備
まず、Python環境とPyTorchがインストールされていることを確認してください。また、必要なライブラリをインストールします。Google Colaboで起動させた方が早い・かつ初心者に便利なので「Colaboratory」で解説します。
・Colaboratory にアクセスしましたら「ノートブックを新規作成」を押下します。
・ノートブック上で以下のコードを入力し「Enter」を押下。
pip install transformers torch
2. モデルのダウンロード
Hugging Faceからモデルをダウンロードします。以下のコードを使用して、モデルとトークナイザーをロードします。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model = AutoModelForCausalLM.from_pretrained("cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese", device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
messages = [
{"role": "user", "content": "AIによって私たちの暮らしはどのように変わりますか?"}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
output_ids = model.generate(input_ids,
max_new_tokens=4096,
temperature=0.7,
streamer=streamer)
・コードを追加を押下
・先述したコードを挿入して「Enter」を押下
普段からColaboを無料で使っている人は容量を食ってしまいますので、メモリを増量させる必要があります。
使用上の注意点
- リソース要件: 特に32Bモデルは大量のメモリと計算能力を必要とします。適切なハードウェアを用意してください。
- バッチ処理: 大量のテキスト処理を行う場合は、バッチ処理を検討してください。
- エラー処理: 適切なエラー処理を実装し、モデルの出力を常にチェックしてください。
「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」の使用方法は、他のHugging Faceモデルと類似しています。しかし、このモデルの特性を最大限に活用するためには、日本語処理に特化した調整やプロンプトエンジニアリングが重要になるでしょう。
まとめ
サイバーエージェントが開発した「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」は、日本のAI開発シーンに大きな影響を与える可能性を秘めたモデルです。以下に、このモデルの主要なポイントをまとめます。
- 高性能な日本語LLM: DeepSeek-R1をベースに、日本語能力を大幅に強化したモデルです。
- 無料で利用可能: Hugging Face上で公開されており、誰でも無料でアクセスできます。
- 商用利用も可能: MITライセンスにより、商用利用を含む幅広い用途で使用できます。
- 複数のバージョン: 14Bと32Bの2つのバージョンが提供されており、用途に応じて選択できます。
- 使いやすさ: Hugging Faceのインターフェースを通じて、比較的簡単に実装できます。
- 日本語特化: 日本語の微妙なニュアンスや文化的文脈の理解に優れています。
- AI開発の加速: このモデルの登場により、日本国内でのAI開発が加
趣味:業務効率化、RPA、AI、サウナ、音楽
職務経験:ECマーチャンダイザー、WEBマーケティング、リードナーチャリング支援
所有資格:Google AI Essentials,HubSpot Inbound Certification,HubSpot Marketing Software Certification,HubSpot Inbound Sales Certification
▼書籍掲載実績
Chrome拡張×ChatGPTで作業効率化/工学社出版
保護者と教育者のための生成AI入門/工学社出版(【全国学校図書館協議会選定図書】)
突如、社内にて資料100件を毎月作ることとなり、何とかサボれないかとテクノロジー初心者が業務効率化にハマる。AIのスキルがない初心者レベルでもできる業務効率化やAIツールを紹介。中の人はSEO歴5年、HubSpot歴1年

