

AI音声生成技術が進化を続ける中、OpenAIが2025年3月に発表した「OpenAI.fm」。このサービスは、特に「GPT-4o Mini TTS」という最新の音声合成モデルを体験できるデモサイトとして注目を集めています。本記事では、OpenAI.fmの概要からGPT-4o Mini TTSの詳細、使い方、料金体系まで、網羅的に解説します。AI音声に関心がある方、高品質な音声コンテンツを制作したい方は必見です。

 所有資格:Google AI Essentials
所有資格:Google AI Essentials
この記事はこんな人におすすめ
・OpenAI.fmとは何か知りたい
・他の音声生成AIと何が違うのか気になる
OpenAI.fmとは?
次世代音声AIが実現する「声の民主化」
OpenAI.fmは、OpenAI社が開発した最新の音声生成AIモデルを試せるウェブサイトです。従来のテキスト読み上げツールとは異なり、人間のような自然な音声を生成できることが特徴です。
OpenAI.fmの核となる技術は、GPT-4o(GPT-4o Mini)アーキテクチャに基づいた音声合成モデル「GPT-4o Mini TTS」です。2024年に発表された研究成果を基に、感情表現や話し方のニュアンスを細かく制御できるようになりました。
このサービスの登場により、ポッドキャスト、オーディオブック、ナレーション付き動画など、様々な音声コンテンツの制作が容易になりました。プロのナレーターや声優を雇わずとも、高品質な音声を誰でも手軽に生成できるようになったのです。
OpenAI.fmは、APIサービスのデモ版として公開されており、現在は無料で利用できます。例えば以下のような音声ボイスがすぐにできます。
GPT-4o Mini TTSとは?
GPT-4o Mini TTSは、OpenAIが開発した軽量かつ高性能な音声合成モデルです。従来の音声合成モデルと比較して、テキストをより自然な音声に変換できる点が特徴です。
- OpenAI製の音声合成モデル
- テキストをより自然な音声に変換
- 話し方の指示が可能
GPT-4o Mini TTSは、GPT-4oとGPT-4o miniのアーキテクチャに基づいており、テキストを高品質かつ自然に聞こえる音声に変換します。
「共感してくれるカスタマーサポートのように話して」など、話し方を指示できるのが大きな特徴です。
GPT-4o Mini TTSの特徴
- 本物の音声データセットで事前トレーニングを実施: GPT-4o Mini TTSは、本物の音声データセットによる事前トレーニングを行っています。音声中心のデータセットで広範囲にわたる事前トレーニングを実施することで、音声の微妙なニュアンスに対してより高精度な音声出力を実現しています。
- 高度な蒸留技術: GPT-4o Mini TTS大規模な音声モデルの知識を小型モデルに効率的に転移する技術を採用しています。これにより、小型モデルでも高品質な音声出力を実現しています。特筆すべきは内部対話シミュレーション機能で、仮想対話環境を生成し実際の会話パターンに近い学習データを自己生成します。この方式により、小規模アーキテクチャながら応答性と音質の両立を実現しています。
- 強化学習の導入: GPT-4o Mini TTSでは強化学習を取り入れることにより、音声認識精度の飛躍的改善、幻聴現象の抑制、複雑な音声パターン解析能力の強化に成功しています。
OpenAI.fmでできること
- マルチスタイル音声合成
OpenAI.fmは、多様な音声キャラクターを提供しています。「Alloy」「Echo」「Fable」「Onyx」「Nova」「Shimmer」など、個性豊かな声質から選択可能です。これらの音声は、ニュース原稿の読み上げからラジオドラマまで、幅広いジャンルに対応しています。
さらに、「VIBE」と呼ばれる設定により、感情やトーン、話し方のスタイルをカスタマイズできます。例えば、「Calm(穏やか)」「Emo Teenager(エモいティーン)」「Medieval Knight(中世の騎士)」といった具合に、シーンに合わせた話し方を指定できるのです。
- リアルタイム音声編集
OpenAI.fmの特徴的な機能の一つが、リアルタイムでの音声編集です。生成された音声をその場で調整し、即座に結果を確認できます。ピッチ、スピード、音量などのパラメータをスライダーで簡単に調整でき、プロフェッショナルな音声編集ソフトのような操作性を実現しています。 - 感情表現の制御
AIによる感情分析と連動し、テキストの内容に応じて自動的に適切な感情表現を付加する機能があります。例えば、喜びや悲しみ、怒りなどの感情を0.1%単位で調整可能です。これにより、より人間らしい、説得力のある音声を生成できます。 - 多言語対応
OpenAI.fmは多言語に対応しており、日本語はもちろん、英語、中国語、スペイン語など、主要な言語での音声生成が可能です。さらに、アクセントや方言のオプションもあり、例えば英語であればイギリス英語やオーストラリア英語といった違いも表現できます。 - 音声認識と翻訳機能
音声入力からテキストへの変換(音声認識)機能も搭載されています。さらに、認識したテキストを別の言語に翻訳し、その言語で音声を生成するという一連の流れをシームレスに行えます。これにより、国際的なコミュニケーションツールとしての活用も期待されています。 - APIによる連携
開発者向けにAPIが提供されており、他のアプリケーションやサービスとの連携が可能です。これにより、OpenAI.fmの音声生成機能を自社のサービスに組み込んだり、独自のアプリケーションを開発したりすることができます。
これらの機能により、OpenAI.fmはプロフェッショナルな音声コンテンツ制作を、誰もが手軽に行えるプラットフォームとなっています。
OpenAI.fmは無料?料金は?
OpenAIのデモサイトでは誰でも手軽に試せますが、ビジネスでの本格導入にはAPIの活用が必要となります。
APIとは、ソフトウェア間で通信するための仕組みで、音声生成技術を自社のウェブサイトやアプリケーションに組み込む際に必要です。API利用を始めるには、アカウントの作成と支払い情報の登録が求められます。 新規ユーザーには$5分の無料クレジットが提供されています。
技術的には、APIを使うためにプログラミングの知識が必要です。PythonなどのプログラミングAAで、OpenAIのAPIにリクエストを送信し、受け取った音声データを処理するコードを作成することになります。
料金については、テキスト入力が1000トークンあたり$0.60、オーディオ出力が1000トークンあたり$12.00となっています。日本語は英語よりもトークン数が多くなる傾向があるため、コスト計算の際には注意が必要です。以下例を作成しましたので参考にしてください。
| サービス | 料金 (1000トークンあたり) | 備考 |
|---|---|---|
| テキスト入力 | $0.60 (約91.80円) | APIにテキストを送信する際のコスト |
| オーディオ出力 | $12.00 (約1,836円) | 音声生成時のコスト |
| テキスト | 言語 | トークン数 | コスト (テキスト入力) |
|---|---|---|---|
| “Hello, how are you today?” | 英語 | 7 | $0.0042 (約0.64円) |
| “こんにちは、お元気ですか?” | 日本語 | 11 | $0.0066 (約1.01円) |
| “今日は天気が良くて、公園に行きたいと思います。” | 日本語 | 28 | $0.0168 (約2.57円) |
| “The weather is nice today, I want to go to the park.” | 英語 | 14 | $0.0084 (約1.29円) |
OpenAI.fmの使い方
OpenAI.fmの使い方はとっても簡単です。
まずはOpenAI.fmにアクセスしましょう。以下の画面が出てきます。
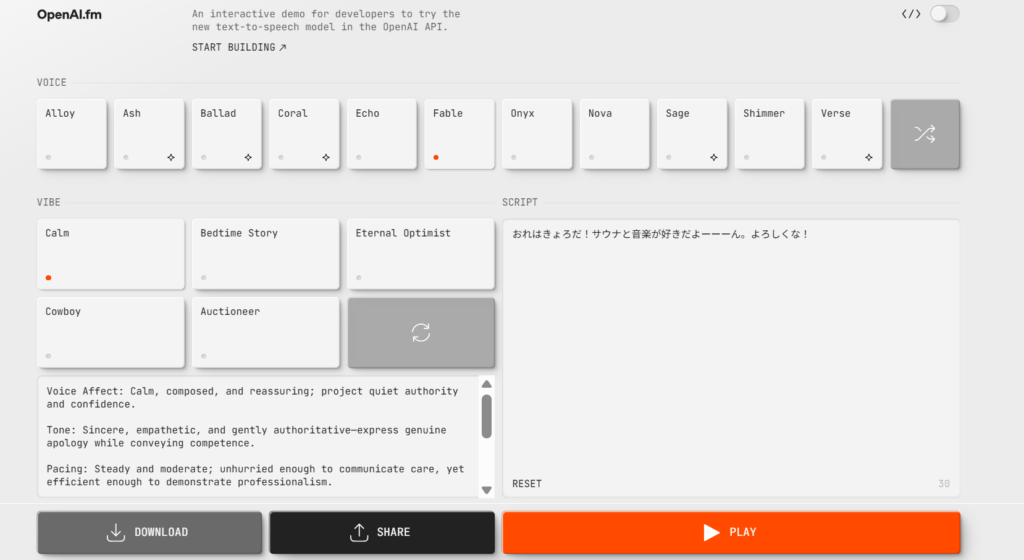
各機能は以下の通りです。
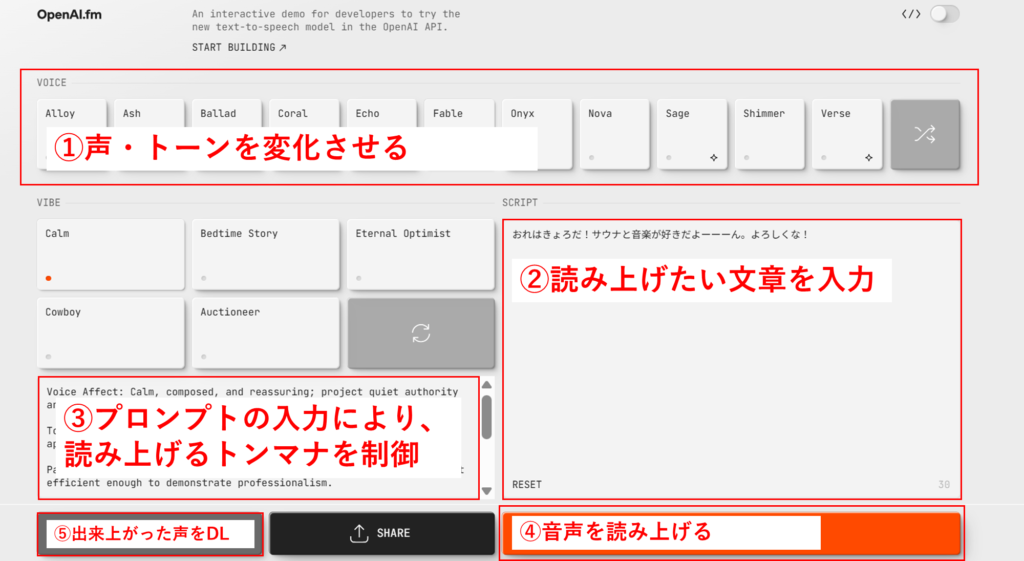
上記は以下のような基本的な機能の役割を持っています。
①声・トーンを選択する
- 上部の「VOICE」セクションから、Alloy、Ash、Ballad、Coral などの声の種類を選択できます
- 各音声は異なる特徴と個性を持っています
②読み上げたい文章を入力する
- 右側の入力欄に読み上げさせたいテキストを入力します
- 例:「おれはさようだ!サウナと音楽が好きだよーーーん。よろしくな!」
- 最大文字数に注意しましょう(入力欄右下に残り文字数が表示されます)
③プロンプトでトーンを制御する
- 下部の「Voice Affect」セクションでは、声の感情や雰囲気を指定できます
- 例:「Calm, composed, and reassuring; project quiet authority」(落ち着いた、構成された、安心感のある声)
- 英語で指示を入力することで、読み上げ方のニュアンスを細かく調整できます
④音声を読み上げる
- 右下のオレンジ色のボタンをクリックすると、入力したテキストが選択した声で読み上げられます
- 生成には数秒かかります
⑤生成された音声をダウンロードする
- 左下の「出来上がった声をDL」ボタンから、生成された音声ファイルをダウンロードできます
- ダウンロードしたファイルは自由に使用できます(OpenAIの利用規約に基づく)
まずは何もチューニングせずに音声を作成してみました。
では上のVOICEを「Nova」に変えてみました。少しイケボになりましたw
次に右下のプロンプトを変えて、トンマナを変えてみました。
Create a tone that sounds like you’re going crazy with a deep voice.
「どすの利いた声でとんでもなく発狂するかのようなトーンで作成して」
できのは以下のボイスです。理想とは違うけど、なんとなくニュアンスはつかんでますね。めっちゃ面白いw
追加機能
- VIBE(雰囲気)設定:Calm、Bedtime Story、Eternal Optimist などのプリセットから選べます
- RESET ボタン:入力をクリアして最初からやり直せます
- SHARE ボタン:生成した音声を共有できます
このデモサイトでは、OpenAI の新しいテキスト読み上げモデルの性能をすぐに試すことができます。ぜひ様々な設定を試してみてください。
OpenAI.fmを使う際の注意点
- 著作権問題
有名人の声真似は技術的には可能ですが、現行ガイドラインでは「本人の書面同意」が義務付けられています。特に商用利用の際には注意が必要です。 - 方言生成の精度
関西弁などの地域方言は85%の精度(2025年3月時点)。特にアクセントの強弱に人工的な響きが残る場合があります。地域によっては、より高精度な音声生成が求められることがあります。 - 超長文処理
1時間を超える音声生成では、文脈の継続性が徐々に低下する傾向があります。30分毎の分割作成が推奨されています。これにより、長時間の音声でも一貫した品質を維持できます。 - 特殊用途制限
医療現場や法廷での使用は明示的に禁止。エンタープライズプランでも契約除外事項となっています。これらの分野では、特定の規制や倫理基準を満たす必要があります。 - リアルタイム生成遅延
高負荷時には最大30秒の遅延が発生する場合があります。緊急時は「Liteモード」への切り替えで速度優先に。これにより、時間に追われるプロジェクトでも迅速に対応できます。
主要音声AI比較表
| サービス | 自然さ | 価格(月額) | 日本語対応 | 独自機能 |
|---|---|---|---|---|
| OpenAI.fm | ★★★★★ | 0~4,800円 | 87ボイス | 3D音響設計 |
| Amazon Polly | ★★★☆☆ | 0.004円/文字 | 15ボイス | AWS連携 |
| Google Cloud TTS | ★★★★☆ | 0.006円/文字 | 22ボイス | リアルタイム変換 |
| ElevenLabs | ★★★★☆ | 5~330ドル | 43ボイス | 声紋複製 |
音声品質ではOpenAI.fmが圧倒的ですが、Google TTSのリアルタイム変換速度(平均0.8秒)には及ばない点が今後の課題です。ただし、OpenAI.fmの3D音響設計や音楽生成連携機能は他社にはない強みです。

ElevenLabsとOpenAI.fmを比較してみた
性能として優秀だなと感じたのは「OpenAI.fm」です。なにより、間の取り方をチューニングせずにできるのがすごい。左が「OpenAI.fm」右が「levenLabs」です。
どちらも違和感はないですが、「気軽に試せて」「日本語に忠実」な点でいうと「OpenAI.fm」に軍配があがりますね。
OpenAI.fmの将来展望
OpenAI.fmは音声生成技術の進化を加速させ、多くの業界に影響を与えています。特に、教育や広告、エンターテインメント分野での活用が期待されています。また、AI音声技術が社会に与える影響についても議論が続いており、倫理的な利用や法的基準の整備が求められています。
将来的には、AI音声技術が人間のコミュニケーションをさらに豊かにし、多様な文化や言語を支援する役割を果たすことが期待されています。特に、視覚障害者や聴覚障害者向けのアクセシビリティ向上にも寄与する可能性があります。
まとめ
OpenAI.fmは単なるテキスト読み上げツールではなく、「音声デザイン」の新時代を切り開くプラットフォームです。特にコンテンツクリエイター向けに提供される「エモーショナルエディット」機能では、視聴者の感情反応をAIが予測し、最適な話し方を自動調整できます。
今後は2025年秋を目処に、脳波計と連動した「集中度可視化システム」の実装が予告されています。音声コンテンツ制作に関わる全ての人が、今すぐ体験すべき画期的なツールと言えるでしょう。

趣味:業務効率化、RPA、AI、サウナ、音楽
職務経験:ECマーチャンダイザー、WEBマーケティング、リードナーチャリング支援
所有資格:Google AI Essentials,HubSpot Inbound Certification,HubSpot Marketing Software Certification,HubSpot Inbound Sales Certification
▼書籍掲載実績
Chrome拡張×ChatGPTで作業効率化/工学社出版
保護者と教育者のための生成AI入門/工学社出版(【全国学校図書館協議会選定図書】)
突如、社内にて資料100件を毎月作ることとなり、何とかサボれないかとテクノロジー初心者が業務効率化にハマる。AIのスキルがない初心者レベルでもできる業務効率化やAIツールを紹介。中の人はSEO歴5年、HubSpot歴1年

