

2025年3月26日、OpenAIは画期的な発表を行いました。ChatGPTの基盤モデル「GPT-4o」に、ネイティブな画像生成機能が統合され、一般提供が開始されたのです。この革新的なアップデートにより、AIによる創造的な画像生成は新たな段階に突入しました。本記事では、GPT-4oの画像生成機能の詳細、その能力、使用方法、そして注意点について詳しく解説していきます。
この記事に興味がある方は以下もおすすめです。




 所有資格:Google AI Essentials
所有資格:Google AI Essentials
この記事はこんな人におすすめ
・画像生成AI機能を活用して漫画を作成したい
・日本語文字を画像に入れたい
GPT-4oの画像生成AIとは?
OpenAIは長い間、言語モデルに画像生成機能を組み込むことが重要だと考えてきました。GPT-4oでは、単に言語モデルに画像生成を追加するのではなく、AIの中核的な能力として画像生成を位置づけるという根本的な発想の転換が行われました。

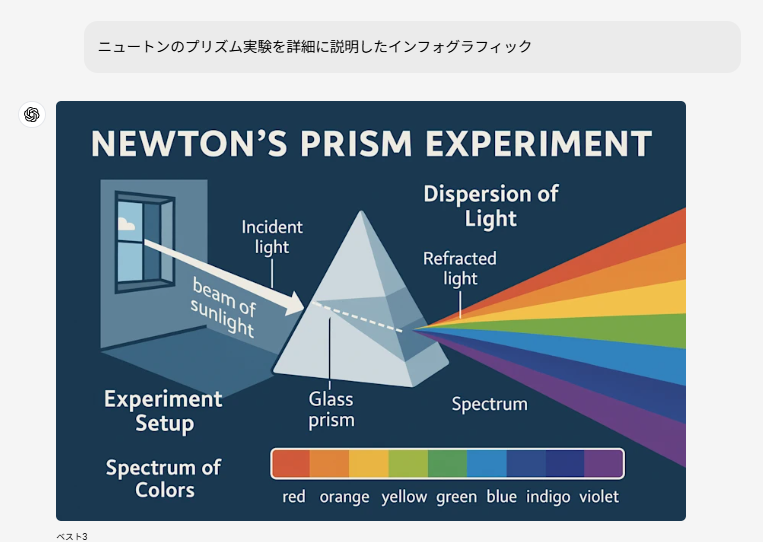
従来のAI画像生成ツールは「美しい」画像を作り出すことに焦点を当てていましたが、GPT-4oでは「実用的で価値のある」画像生成にシフトしています。これは人間が画像を使う本来の目的—コミュニケーション、説得、分析—に焦点を当てたものです。
GPT-4oの主要な画像生成AI機能
GPT-4oの画像生成機能における最も重要な技術革新は、以下の点にあります。
マルチモーダルな基盤技術の詳細
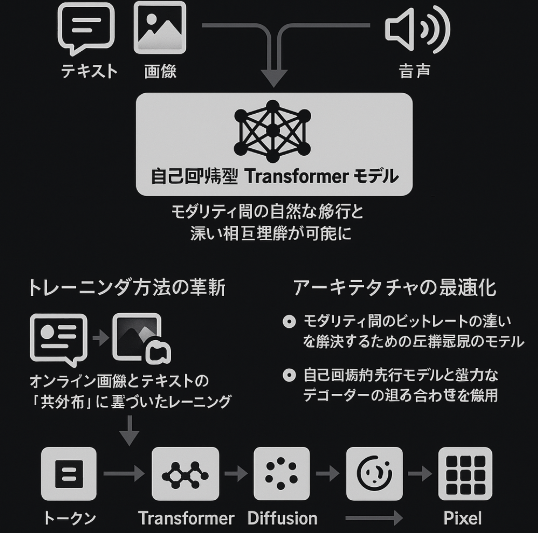
GPT-4oの画像生成における革新的なアプローチは、その基盤技術にあります。OpenAIは以下のような技術的アプローチを採用しています。
- 統合モデリング手法
- テキスト、画像、音声を
p(text, pixels, sound) [equation]という一つの大きな自己回帰型Transformerモデルで直接モデル化 - これにより、モダリティ間の自然な移行と深い相互理解が可能に
- テキスト、画像、音声を
- トレーニング方法の革新
- オンライン画像とテキストの「共分布」に基づいたトレーニング
- 画像が言語とどう関連するかだけでなく、画像同士がどう関連するかも学習
- 積極的な事後トレーニング(post-training)による視覚的流暢性の向上
- アーキテクチャの最適化
- モダリティ間のビットレートの違いを解決するための圧縮表現のモデル化
- 自己回帰的先行モデルと強力なデコーダーの組み合わせを採用
トークン -> [transformer] -> [diffusion] -> ピクセルというパイプラインの実装
テキストレンダリングの精度
GPT-4oによるテキストレンダリングの改善は、特に実用面で革命的です。
- 精密なテキスト配置:「一枚の写真は千の言葉に値しますが、適切な場所にいくつかの言葉を生成することで、画像の意味を高めることができます」という考え方に基づき、テキストと画像の有機的な統合を実現
- 複雑なテキストレイアウト:
- 道路標識の例では、複数の詳細な規則(駐車制限、清掃時間など)と架空の要素(「魔女のほうき駐車禁止」など)を組み合わせた複雑なテキストを自然に描画
- 韓国料理レストランのメニューでは、料理名、価格、詳細な説明を適切なレイアウトで表示

- デザイン性の高いテキスト表現:
- 結婚式の招待状例では、エレガントなタイポグラフィとエンボス加工表現を再現
- フォントスタイル、サイズ、配置の繊細な調整が可能

マルチターン対話による画像編集
GPT-4oのネイティブな画像生成能力により、自然な対話を通じた段階的な画像編集が可能になりました。
- 継続的なスタイル一貫性:
- 猫キャラクターの例では、探偵帽と片眼鏡を追加した後、ビデオゲームUIを追加し、さらに視点変更、環境変更を行っても、キャラクターの一貫性が保持される
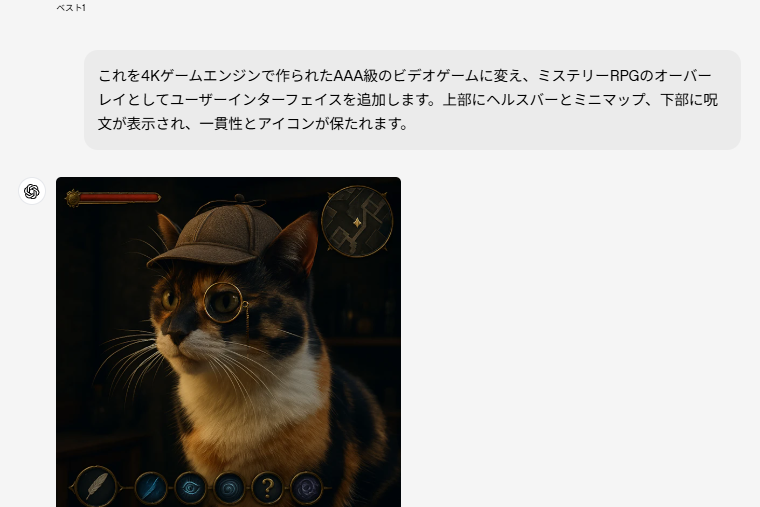
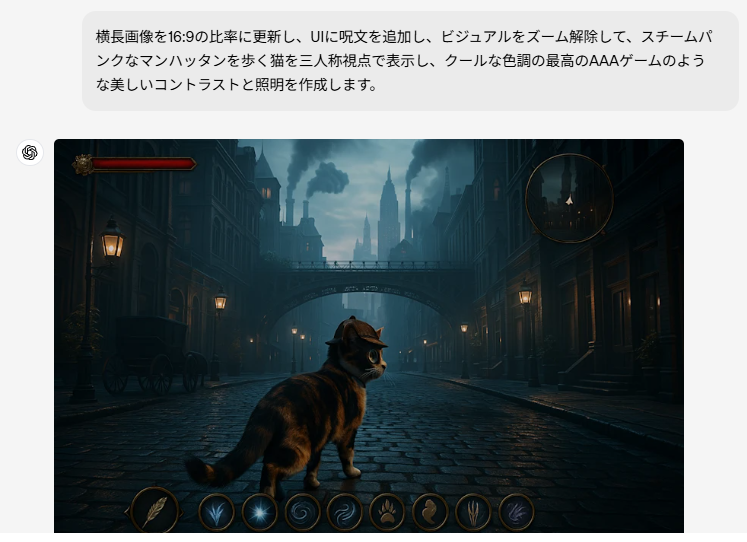
- 複雑な編集指示の理解:
- 「16:9比率に更新」「UIに呪文を追加」「三人称視点に変更」「スチームパンクなマンハッタン」など、複数の異なる指示を同時に理解し実行
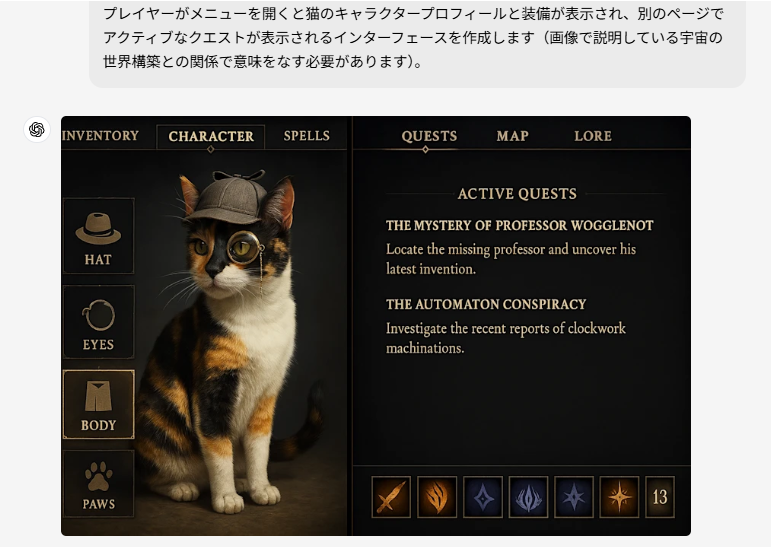
- 機能的UIの段階的構築:
- ゲームインターフェースの例では、単なる装飾ではなく、キャラクタープロフィール、装備、クエスト情報など、実際のゲームで機能するであろうUIデザインを作成
インコンテキスト学習と参照画像の活用
GPT-4oは、ユーザーがアップロードした画像を深く理解し、その特徴や概念を新しい生成に活かせます。他が5~8 個のオブジェクトを処理するのに苦労するのに対し、GPT-4oは最大10~20 個の異なるオブジェクトを処理できます。オブジェクトをその特性や関係に密接に結び付けると、より適切な制御が可能になります。
- 視覚的概念の抽出と応用:
- 三角車輪の例では、参照画像から三角形の車輪という概念を抽出し、完全に新しい車両デザインに応用
- さらに「英国特許」として文書のスタイルも適切に反映

- 環境の変更と一貫性維持:
- 三角車輪車両を「ニューヨーク市で撮影した写真」に配置する指示では、都市環境に合わせたリアルな配置を実現しつつ、元のデザイン要素を保持

- スタイル変換と機能的理解:
- チェーンソーの例では、製品画像から広告イメージへの変換を行い、「おばあちゃんが感謝祭の七面鳥を切り分ける」という予想外の文脈でも製品の機能を活かした描写を実現

世界知識の活用と視覚化
GPT-4oは、テキストとして持っている知識を視覚的に表現する能力が顕著に向上しています。
- プログラミングコードの視覚化:
- Three.jsコードから、そのコードが表現しようとしている3Dシーン(OpenAIバナー)を正確に視覚化

- 複雑な科学概念のインフォグラフィック:
- 「サンフランシスコがなぜ霧深いのか」という気象学的現象を、視覚的に分かりやすく説明するインフォグラフィックを作成
- データと視覚要素を効果的に組み合わせた説明的画像の生成

- 専門知識を視覚化:
- カクテルレシピを視覚的に魅力的に表現
- クジラの種類の教育ポスター
- 抹茶の作り方を説明するリソグラフ

GPT-4oの画像生成能力が飛躍的に向上した背景
GPT-4oの画像生成能力が飛躍的に向上した背景には、OpenAIが取り組んできた複数の重要な技術革新があります。ホワイトボードの写真に描かれていた数式やダイアグラムが示すように、この進化は単なる機能追加ではなく、AIの思考方法そのものを変える根本的なアプローチの変化によるものです。
モデルアーキテクチャの革新
まず特筆すべきは、モデルアーキテクチャの革新です。GPT-4oでは、テキスト、画像、音声といった異なる種類の情報(モダリティ)を一つの自己回帰型Transformerモデルで直接処理できるようになりました。従来は別々に扱われていたこれらの情報が、同じ「言語」で会話できるようになったのです。例えるなら、翻訳者を介さずに直接対話できるようになったといえるでしょう。これにより、「探偵の猫をゲームキャラクターに変換して、UIを追加して…」といった複雑な指示に対しても、途中で意図が失われることなく一貫した処理が可能になりました。
トレーニングデータの質と多様性
またトレーニングデータの質と多様性も重要な要素です。OpenAIは単に「テキストに対応する画像」を学習させるだけでなく、「画像同士の関係性」まで学習させる手法を採用しました。例えば「水彩画風のクジラ」というプロンプトでは、クジラの知識と水彩画というスタイルを別々に理解し、それらを自然に組み合わせられるようになっています。これは人間が「青いリンゴを描いて」と言われた時に、リンゴの形状と青色という概念を組み合わせられるのに似ています。

深い言語理解と視覚的表現の連携
深い言語理解と視覚表現の連携も見逃せません。GPT-4oは「空っぽの街」という抽象的な概念を、タイムズスクエアや渋谷という具体的な場所の知識と組み合わせ、通常は人で賑わうこれらの場所から人や車、電飾看板を取り除いた静謐な風景として表現できます。これは単なる画像生成ではなく、言語で表現された概念を視覚的に解釈して表現する高度な能力です。

複雑な指示への追従能力
- 10〜20もの異なるオブジェクトや概念を一度に処理し、適切に配置できる
- 例えば16個の異なるオブジェクトをグリッド状に配置する例では、各オブジェクトの特性(色、形、パターン)を正確に反映
GPT-4oの画像生成能力は、単なる「きれいな画像を作る」機能ではなく、言語理解と視覚表現を深いレベルで統合した真のマルチモーダルAIへの進化を示しています。これにより、人間のコミュニケーションや創造的作業をより自然にサポートする可能性が大きく広がっています。
GPT-4oで漫画製作が可能に?
日本語テキストのレンダリング
GPT-4oで大きく改善された機能の一つが多言語対応です。以前のモデルでは非ラテン文字、特に日本語などのアジア言語の描画に問題がありましたが、GPT-4oではこの点が改善されています。
日本語のテキストレンダリングについては、以下のような用途が考えられます。
- 看板やポスター: 日本語のテキストを含む看板や広告ポスターの生成
- 漫画のセリフ: 吹き出し内の日本語テキスト表示
- メニュー: 和食レストランのメニューデザイン
- 教育資料: 日本語学習者向けの図解付き教材
実際に作成した画像は以下です。これ、本当にバナー作成の手間とか省けると思います。

ただし、長文や複雑な漢字、細かな書式指定については依然として課題が残っています。OpenAIは多言語テキストレンダリングを「現在の制限」の一つとして挙げており、今後も改良が続けられる予定です。
漫画・コミック制作機能
GPT-4oの画像生成能力は、漫画やコミック制作においても革新的な可能性を秘めています。
- 複数コマ漫画: 4コマ漫画などの短いストーリーを一度に生成できます。
- キャラクターデザイン: キャラクターのコンセプトアートを作成し、視点や衣装を変えながら一貫性を保てます。
- スタイル指定: 特定の漫画スタイル(少年漫画、少女漫画など)を指定した生成が可能です。
- コマ割りとレイアウト: 異なるアングルや構図を持つページデザインを作成できます。
実際に以下のように作成できました。

OpenAIが公開している例では、カタツムリが車のショールームを訪れる4コマ漫画が紹介されています。各コマには背景、キャラクター、セリフがあり、最後にオチがついています。このような構造化されたストーリーテリングが可能になったことは、クリエイターにとって大きな武器となるでしょう。
『GPT-4o』画像生成AIの使い方
GPT-4oの画像生成機能を利用するには、以下のような手順を踏みます。
・ChatGPTを開き、GPT-4oモデルを選択します。これで使用準備は可能です。
・必要に応じて、アスペクト比(16:9など)や特定の色(HEXコードでの指定も可)などの詳細を指定しプロンプトを打ちます。
・透過背景が必要な場合は、その旨を明示的に伝えます。
・生成された画像に対して、さらに修正や調整の指示を出すことができます。
日本語の文字を入れる
「aiワークスタイルのきょろ と手紙に打った画像を作成して」と打ってみました。文字入れ完璧ですね

スタイルを維持する
さらに「これスタイルを維持したままリアル人間でマッチョな感じにできる?」と打ってみました。

背景透過
「背景透過もいける?」と打ってみました。流石ですね。

キャラクターの一貫性維持
「キャラクターの一貫性を維持したままカフェにいるシーンの画像を生成する」と打ってみました。完璧です。

GPT-4oで画像生成をする際の実践的な活用例
1. ビジネスプレゼンテーション
会議資料やプレゼンテーションスライドに使用する視覚的な要素を短時間で作成できます。
以下は、GPT-4oモデルを図にしたものです。
例:「当社の新製品ラインナップを表すインフォグラフィックを作成してください。製品A(青)、製品B(赤)、製品C(緑)の3種類を比較し、それぞれの特徴を視覚的に表現してください。背景は白で、企業ロゴを右上に配置してください。」
2. 教育コンテンツ
教師や講師が授業で使用する説明図や視覚教材を簡単に作成できます。

例:「中学生向けの光合成のプロセスを説明する図を作成してください。太陽光、二酸化炭素、水がどのように糖と酸素に変換されるかを示し、それぞれの要素に日本語でラベルをつけてください。」
3. SNSコンテンツ
ソーシャルメディア向けの視覚的に魅力的なコンテンツを作成できます。
例:「当社の新商品『うるおい美容液』のInstagram投稿用画像を作成してください。製品ボトル(透明で中身は薄いピンク色)と、使用感を表す水滴のビジュアルを含め、『うるおい続く、24時間。』というキャッチコピーを入れてください。」
4. Webデザイン
ウェブサイトやアプリのプロトタイプやデザイン要素を迅速に作成できます。

例:「オーガニック食品配送サービスのランディングページ上部に使用するヒーロー画像を作成してください。新鮮な野菜と果物が詰まったバスケットと、配送ボックスを開ける人の手が写っている画像で、右側に『新鮮をお届け』というテキストを配置してください。」
GPT-4oの画像生成AIを利用できるプランは?
GPT-4oの画像生成機能は、2025年3月26日から順次提供が開始されています。
| プラットフォーム | 利用プラン | 提供状況 | 特記事項 |
|---|---|---|---|
| ChatGPT | Plus, Pro, Team, Free | 利用可能 | デフォルトの画像生成機能として利用可能 |
| Enterprise, Edu | 近日提供予定 | 具体的な提供開始日は未発表 | |
| 開発者向けAPI | すべてのAPI利用者 | 近日提供予定 | 発表から数週間以内に提供開始予定 |
| DALL·E | すべてのユーザー | 利用可能 | 専用の「DALL·E GPT」から従来版を引き続き利用可能 |
| Sora.com | Pro, Plus, Team, Free | 利用可能 |
|
GPT-4oで画像生成する際の注意点と限界
GPT-4oの画像生成機能は非常に強力ですが、いくつかの限界と注意点があります。OpenAIも公式サイトでこれらの制約を認めており、今後のアップデートで解決していく意向を示しています。
1. クロッピングの問題
長い画像(ポスターなど)を生成する際、特に下部が切り取られてしまうことがあります。これは特に、一枚の画像に多くの情報を詰め込もうとする場合に発生しやすい問題です。

対処法:
- 画像を複数に分割して生成する
- 重要な情報は上部または中央に配置する
- アスペクト比を明示的に指定する
2. ハルシネーション(幻覚)
他のAIモデルと同様に、GPT-4oも事実に基づかない情報を生成することがあります。特に情報が少ないプロンプトの場合、この問題が発生しやすくなります。
対処法:
- できるだけ具体的で詳細なプロンプトを使用する
- 生成された画像の内容を慎重に確認する
- 必要に応じて追加の修正指示を出す
3. 複雑な概念の結合問題
GPT-4oは10〜20程度の異なる概念を一度に処理できますが、それ以上になると正確性が低下します。例えば、周期表の全元素を正確に描画するなどの高度な課題では苦戦する場合があります。
対処法:
- 複雑な情報は分割して生成する
- 一度に指定する概念や要素の数を制限する
- 重要な部分に焦点を当て、詳細に指示する
4. 多言語テキストのレンダリング
非ラテン文字、特に日本語や中国語などの複雑な文字体系のレンダリングには依然として課題があります。文字が不正確になったり、存在しない文字が生成されたりする場合があります。
対処法:
- 短いフレーズから始め、徐々に複雑な文を試す
- フォントサイズを大きめに指定する
- 画像内のテキスト量を制限する
5. 編集精度の問題
既に生成された画像の特定部分(例:誤字)を修正するよう指示しても、常に正確に対応できるわけではありません。また、修正を試みると意図しない部分も変更されることがあります。
対処法:
- 大きな変更よりも小さな修正を重ねる
- 修正が難しい場合は、新しく画像を生成し直す
- 編集指示はできるだけ具体的かつ明確にする
6. 小さなテキストの密集問題
非常に小さいサイズで詳細な情報を描画するよう求められると、GPT-4oは苦戦します。特に、多くの文字情報を小さなスペースに詰め込もうとした場合、判読不能になる可能性があります。
対処法:
- テキストサイズを大きく保つ
- 情報を複数の画像に分散させる
- 読みやすさを優先し、情報量を適切に調整する
MidjourneyとGPT-4oの日本語文字画像を比較してみた
Midjourneyでも日本語文字の打ち込みが可能となっています。実際に以下はMidjourneyとChatGPTのGPT-4oの日本語文字画像の品質の高さを比較してみました。
左はMidjourney、右がChatGPTです。文字はChatGPTに軍配!Midjourneyはビジュアルがすごい!


GPT-4oの画像生成AIに関する今後の展望
改善が期待される分野
OpenAIは現在認識している制限に対して、今後のモデル改善を通じて対応していく方針を示しています。特に以下の分野での進化が期待されます:
- 多言語サポートの強化: 日本語を含む非ラテン文字の正確なレンダリング
- 編集精度の向上: 特定部分のみを正確に編集できる機能
- 高密度情報の処理: 小さなテキストでも読みやすく表示できる能力
- より複雑な概念の結合: 20を超える異なる概念を一度に処理できる能力
安全性対策の進化
OpenAIはGPT-4oの画像生成における安全性確保にも注力しています。主な取り組みとして以下がございます。
- C2PAメタデータの付与: 生成された全ての画像にはC2PAメタデータ※が含まれ、GPT-4oによって生成されたことを識別できます。
- 内部検索ツールの開発: 技術的な属性を使用して、コンテンツがモデルから生成されたかどうかを検証するための内部検索ツールを構築しています。
- コンテンツポリシーの強化: 児童性的虐待材料や性的ディープフェイクなど、ポリシーに違反する可能性のある画像生成リクエストをブロックする仕組みを導入しています。
- リアルな人物の保護: 実在の人物の画像がコンテキストにある場合、どのような種類の画像が作成できるかについての制限を強化し、特にヌードや暴力的なコンテンツについては堅牢な保護措置を設けています。
- 推論を活用した安全性: 人間が書いた解釈可能な安全仕様から直接作動する推論LLMを訓練し、ポリシーの曖昧さを特定して対処するのに役立てています。
※「誰が、いつ作成したか」といった情報を、コンテンツのクリエイター自らが作成したコンテンツに追記したもの
まとめ
ChatGPT『GPT-4o』の画像生成AIの進化は、単なる技術的な進歩を超えて、私たちの創造的表現の可能性を大きく広げるものです。テキストと画像を融合させた表現、日本語対応、マンガ制作、多様なスタイル変換など、これまでのAIツールでは難しかった機能が実現されています。
もちろん、現時点ではいくつかの制限や課題も存在しますが、OpenAIは継続的な改良を進めており、今後のアップデートでさらなる進化が期待されます。
GPT-4oの画像生成機能は、プロのクリエイターから一般ユーザーまで、幅広い人々の創造的な表現活動を支援する強力なツールとなるでしょう。特に日本のコンテンツ産業において、この技術がどのように活用され、新たな表現や制作プロセスを生み出していくのか、今後の展開が楽しみです。
趣味:業務効率化、RPA、AI、サウナ、音楽
職務経験:ECマーチャンダイザー、WEBマーケティング、リードナーチャリング支援
所有資格:Google AI Essentials,HubSpot Inbound Certification,HubSpot Marketing Software Certification,HubSpot Inbound Sales Certification
▼書籍掲載実績
Chrome拡張×ChatGPTで作業効率化/工学社出版
保護者と教育者のための生成AI入門/工学社出版(【全国学校図書館協議会選定図書】)
突如、社内にて資料100件を毎月作ることとなり、何とかサボれないかとテクノロジー初心者が業務効率化にハマる。AIのスキルがない初心者レベルでもできる業務効率化やAIツールを紹介。中の人はSEO歴5年、HubSpot歴1年

